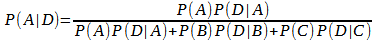Olá! É sempre um prestígio ter você aqui.
Nesta publicação, você aprenderá sobre:
-
teorema de Bayes;
- independência entre eventos,
- provas repetidas e
independentes,
- eventos mutuamente exclusivos.
Desejo a você uma boa aprendizagem!
A probabilidade condicionada, isto é, a probabilidade de um evento ocorrer dado que outro ocorreu, leva-nos à relação
Também podemos escrever
Assim, a interseção entre A e B podem ser dadas pelos produtos:
Podemos também escrever:
O resultado mais relevante, nesse contexto é o seguinte teorema:
Por indução, tem-se que:
sendo os Ai eventos quaisquer.
Calma! Vamos fazer
com 3, primeiro?
Tudo bem até aí? Perceba que temos mais uma interseção para
“desmembrar”. Isto é:
Agora ficou mais fácil visualizar a expressão com n eventos.
Vamos a outro
teorema de grande importância em probabilidade: o teorema de Bayes.
Considere que os
eventos
formem uma partição de um espaço amostral S. Isto significa que
são mutuamente exclusivos, e que sua união resulta em S. Considere
outro evento qualquer de S, digamos B. Então:
Disso, segue-se que
E do Teorema da Multiplicação:
Sabemos ainda que, para qualquer evento Ai, a
probabilidade condicional de Ai dado B é dada por:
Fazendo as substituições adequadas, temos:
Isto é, o Teorema de Bayes.
Vejamos alguns
exemplos da utilidade desse teorema.
Primeiro exemplo:
considere que três robôs – A, B, e C – são responsáveis por
50%, 30%, e 20% de todas as operações num pregão da bolsa de
valores brasileira. As percentagens de operações com prejuízo
desses robôs são 3%, 4% e 5%, nesta ordem. Se uma operação for
escolhida aleatoriamente, qual a probabilidade de ela ter resultado
em prejuízo?
Para início, você
precisa enxergar as relações entre os eventos dados. Você sabe que
a operação deve resultar em prejuízo, mas não sabe de que robô
ela partiu. Portanto, devemos considerar a probabilidade conjunta das
interseções entre “operação com prejuízo” e “partiu do
robô Y”, para este resultado. Em símbolos, sendo D a “operação
com prejuízo”:
Isto é:
Segundo exemplo: dadas as condições do primeiro exemplo, foi
escolhida aleatoriamente uma operação. Calcule a probabilidade de
ela ter sido disparada pelo robô A.
Agora você tem a
probabilidade da “operação com prejuízo”, calculada no
primeiro exemplo, e quer a probabilidade de ter sido disparada pelo
robô A. Isto é, a probabilidade de A, dado que D ocorreu.
Exercício 1: para a situação do segundo exemplo, calcule a
probabilidade de a operação que resultou em prejuízo ter partido
do robô B. Depois, calcule para o robô C.
Exercício 2: use
diagramas de árvore para resolver o primeiro exemplo.
Quando a probabilidade de um evento A ocorrer não afetar a
probabilidade de outro evento B ocorrer, dizemos que A é
independente de B. Mas isso significa que a probabilidade de A
dado B é a própria probabilidade de A:
Sendo assim, também vale que
A última igualdade servirá como definição para eventos
independentes.
Vamos definir o
seguinte experimento: três lançamentos de uma moeda não viciada.
Se usarmos X para cara e U para coroa, o espaço equiprovável é
S = {XXX. XXU, XUX,
UXX, XUU, UXU, UUX, UUU }
Sejam os eventos
A = {primeiro
lançamento é U},
B = {segundo
lançamento é U}, e
C = {ocorre XX, isto
é, exatamente duas caras consecutivas}.
Exercício 3:
verifique as relações de dependência ou independência entre os
três eventos listados.
No exercício 3, é
fácil verificar, usando a definição matemática de independência,
as relações citadas. Mas eu gostaria de que você explicasse, com
palavras, cada relação.
Exemplo 1: Na
próxima semana, a probabilidade de a ação A subir na próxima
semana é de ¼, enquanto a probabilidade de a ação B subir é de
2/5. Sabendo que os preços dessas ações não se influenciam
mutuamente, qual a probabilidade de que uma delas suba na próxima
semana?
Considere A = {alta
da ação A na próxima semana}, e B = {alta da ação B na próxima
semana}. Desde que os eventos são independentes, temos:
Ou seja, a probabilidade de que uma das duas suba é de 0,55, ou
seja, 55%.
Exercício 4: em uma
competição de tiro ao alvo, Camilo tem 1/3 de chances de acertar o
alvo, enquanto Wagner tem 3/4 de chances de acertar o alvo. Se ambos
atiram no alvo, qual é a probabilidade de o alvo ser atingido?
Pegando carona no
nosso exercício 4, podemos formular um exemplo para falar de outro
conceito, que na verdade já apareceu de forma indireta acima. É o
seguinte: suponha que Wagner seja capaz de acertar o alvo com
probabilidade de 0,95, e que ele atirará 30 vezes. Temos aí, um
fenômeno que tem apenas dois resultados possíveis: acertar ou errar
o alvo. Ainda mais, a probabilidade de acertar ou errar continuam as
mesmas para cada uma das 30 repetições.
Para esse tipo de
fenômeno, frequentemente chamamos um resultado de sucesso e o outro
de fracasso. As probabilidades de um e de outro serão representadas,
respectivamente por p e q. O número de repetições será
representado por n.
Mais
especificamente, se o experimento pode ser repetido um número fixo
de vezes, os resultados das provas não se afetam mutuamente (são
independentes), só há dois resultados possíveis (sucesso ou
fracasso), e as probabilidades são constantes, estamos diante de uma
distribuição de probabilidade binomial.
Por exemplo, cada
lâmpada testada, de um conjunto de 5 lâmpadas selecionadas
aleatoriamente em uma fábrica, acende ou não acende. Podemos dizer
que 5 é o número de repetições, que o sucesso é acender e que o
fracasso é não acender. Precisamos das probabilidades de acender e
de não acender.
Digamos, então, que
a probabilidade de acender serja 0,98 e, daí, a probabilidade de não
acender é 0,02. Poderíamos estar interessados em saber qual a
probabilidade de que duas das cinco lâmpadas não acendam.
Já sabemos que as
provas são independentes e que podemos multiplicar as
probabilidades, de sucesso (não acende) e de fracasso (acende):
(0,02)(0,02)(0,98)(0,98)(0,98)
= (0,02)2(0,98)3 = 0,00038
Mas falta saber de
quantas maneiras podemos retirar duas lâmpadas entre cinco.
Agora basta multiplicar 0,00038 10 =
0,0038 ou 0,38% de chances de que duas não acendam.
Em casos desse tipo,
surge uma variável aleatória (VA) X no espaço amostral S de
um experimento. A VA é uma função de S no conjunto dos números
reais R, tal que cada intervalo em R tem como imagem inversa um
evento de S.
A partir da VA,
obtemos o que se chama de distribuição de probabilidade, que
também é uma função (de probabilidade) de X, definida pela
associação de uma probabilidade a cada ponto de x de X(S) = {x1,
x2, …, xn}.
Por aqui ficamos,
mas você continua com o compromisso de resolver mais exercícios
sobre esse assunto. Aproveite para compartilhar seus exercícios
resolvidos com seus colegas, pois Aprender é a nossa Melhor Habilidade!
Siga-me no Instagram.
Um forte abraço e
até breve!